Da ich Anwendungen schreibe die weltweit im Einsatz sind mache ich die Lokalisierung seit über 20 Jahren selbst. Die Texte sind dabei in einer Datenbank gespeichert. Meist
MSSQL aber z.T. auch in AbsoluteDB wenn keine größere Datenbank erforderlich ist. Dafür habe ich mir auch verschiedene Tools geschrieben für export und import von Übersetzungen, da wir diese meist von den Kunden machen lassen (Ich kann weder chinesisch noch ...). An der Oberfläche nutze ich die TAG-Eigenschaft. Ist ein Tag = 1, dann wird der entsprechende Text beim Laden des Formulars übersetzt. Weiterhin habe ich eine globale Umschaltung für Fettschrift implementiert, da diese je nach Sprache (Zeichensatz) anpassbar sein sollte. Das mache ich dann mit Tag = 1 oder Tag = 2.
In der Datenbank habe ich dann z.B. folgende Felder:
LangID (Sprachkennung)
Part (z.B. der Form-Name oder aber auch GLOBAL für globale Texte, ALARM für Alarmtexte etc.)
Entry (z.B. der Name der Komponente oder aber auch sonstige Kennungen wie "ALARM0001" oder "strYes")
Text (der zur Sprachkennung passende Text)
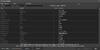
Ich habe auch einen Standarddialog erstellt, der es dem Endkunden erlaubt Texte zur Laufzeit anzupassen. Das ist erforderlich, da oftmals die Übersetzung vom Kontext abhängt.
Geladen wird immer ein kompletter Part. Es ist also für die Übersetzung eines kompletten Forms (Dialog...) nur ein
SQL-Zugriff erforderlich.
Das ganze geht ohne merkliche Verzögerung und läuft sehr zuverlässig. Ich schreibe das, da ich mich über die Jahre - bis auf ein paar Ausnahmen - von gekauften Bibliotheken unabhängig gemacht habe. In der Vergangenheit wurden leider immer wieder tolle Komponenten vom Markt genommen.
Soviel vielleicht mal als Anreiz sowas "zu Fuß" zu machen.
Der Spracheditor präsentiert sich z.B. so:
Man sollte nie so viel zu tun haben, dass man zum Nachdenken keine Zeit mehr hat. (G.C. Lichtenberg)